Blending Artist Styles Together with Stable Diffusion and LoRA

NOTE: This post is probably best viewed on a desktop computer, as the images are quite large. Right click -> Open in New Tab for best viewing
In my last post, I walked through using replicate.com to fine-tune concepts into Stable Diffusion using LoRA weights, with the goal of generating artistic self-portraits and digital paintings of myself. The LoRA trainer on replicate allows you to train three sorts of concepts: face, object, and style.
At the end of the post, as I was getting pretty good results with a face concept, I figured it was worth trying to train a style concept. I trained a custom style based on some stock toy-face images I had. I was honestly surprised that the style concept worked so well and that I was able to mix a face concept with a style concept in a single prompt. Here’s one example, more in the other post.


This got me thinking, “maybe it would be cool to build a LoRA weights library so I can mix and match a bunch of styles!”
The Evolution of Stable Diffusion and Working With Artist Styles
When Stable Diffusion was first released, there was a massive wave of interesting imagery. I remember scrolling https://lexica.art for over an hour, in complete awe, when it first launched. As I was inspecting the prompts, I noticed that nearly 100% of good images were generated using a prompt that included the name of an artist. Intuitively this made sense to me; invoking the name of an artist or specific style would nudge the model toward a particular look and feel.
Unfortunately, this practice led to some bad outcomes for popular artists like Greg Rutowski, whose style was being used en masse without permission. Here’s a Reddit thread conversation discussing the scale of the problem.
In the release of Stable Diffusion 2.0 and 2.1, Stability.ai removed the ability to reference artists by name in image prompts. They’ve also built https://haveibeentrained.com/, where you can register and opt out from having your imagery used for the training of future Stable Diffusion models. Giving artists the ability to opt out seems like a step in the right direction.
In the Stable Diffusion 1.5 era, I was interested in generating large complex stylized, and organic patterns, such as ocean swells. After a day or so of playing, I found that invoking the names of Moebius and Killian Eng nudged the model toward a style that I really connected with. Here is a collection of 4 images I generated back in September using the prompt ocean swells, by killian eng, by moebius




Now, fast-forward to today, with Stable Diffusion 2.1, the results you will get from the same prompt are very different! This, again, is because the artist names were removed from the embeddings. So while the model was still trained with the artwork of these artists, you can’t reference them directly by name.




Making Custom Artist Styles With Stable Diffusion and LoRA
That leads us to today’s post, where we will walk through how to curate a custom training set of images artists that inspire you, and then we'll experiment with blending the styles of multiple artists using LoRA and Stable Diffusion.
But first, a bit of a disclaimer! I recognize that training a model on someone else's work is a bit of a gray area. So I want to make it clear that my intention with this post is to explore imitating artistic elements from artists that inspire me; much like an art student learns to imitate the style of a master painter like Rembrandt.
I will not be sharing the raw training set, nor will I be sharing the LoRA weights I have shared. If you're interested in doing something similar for a personal project, I encourage you to collect and curate images that inspire you and use them to apply limited aspects of color, texture, and composition to your own imagery; to generate something truly unique.
That said, let’s dive in!
1. Collect and Curate a Training Set of Images
If we want to make a style that resembles that of a particular artist, we must first collect 20-30 images of their work.
One strategy for doing this is to search for the artist on google images, and collect them one-by one. I've had mixed results with this strategy, as I'll get a bunch of the same image, or images that are too small, or images that are not from the artist I'm searching for. So Google Images can be a bit tedious.
I found that a more nuanced strategy for collecting images from a specific artist is to search the LAION dataset. LAION is interesting because Stable Diffusion was trained on a 2-billion image subset of the 5-billion image dataset.
Simon Willison has an excellent blog post about exploring the LAION dataset, and making a datasette web UI. He was able to index the improved_aesthetics_6plus subset which consists of 12 million images with an aesthetics score of 6 or higher. I’m not clear on how the aesthetics score is calculated exactly, but it seems to be a pretty good filter of “this image is artwork”.
Check out Simon's awesome LAION Improved Aesthetics 6.0+ datasette catalog. Using this website, you can search by artist name and filter on details such as text, width, height, aesthetics score, etc.
For this post, I'd like to create some images that combine the styles of the artists Moebius and Killian Eng. To find relevat images, I searched for moebius, and killian eng, and filtered out images smaller than 512x512px. The idea with this filter was to ensure that every image was at least the minimum size of a default Stable Diffusion frame (of 512x512 pixels).
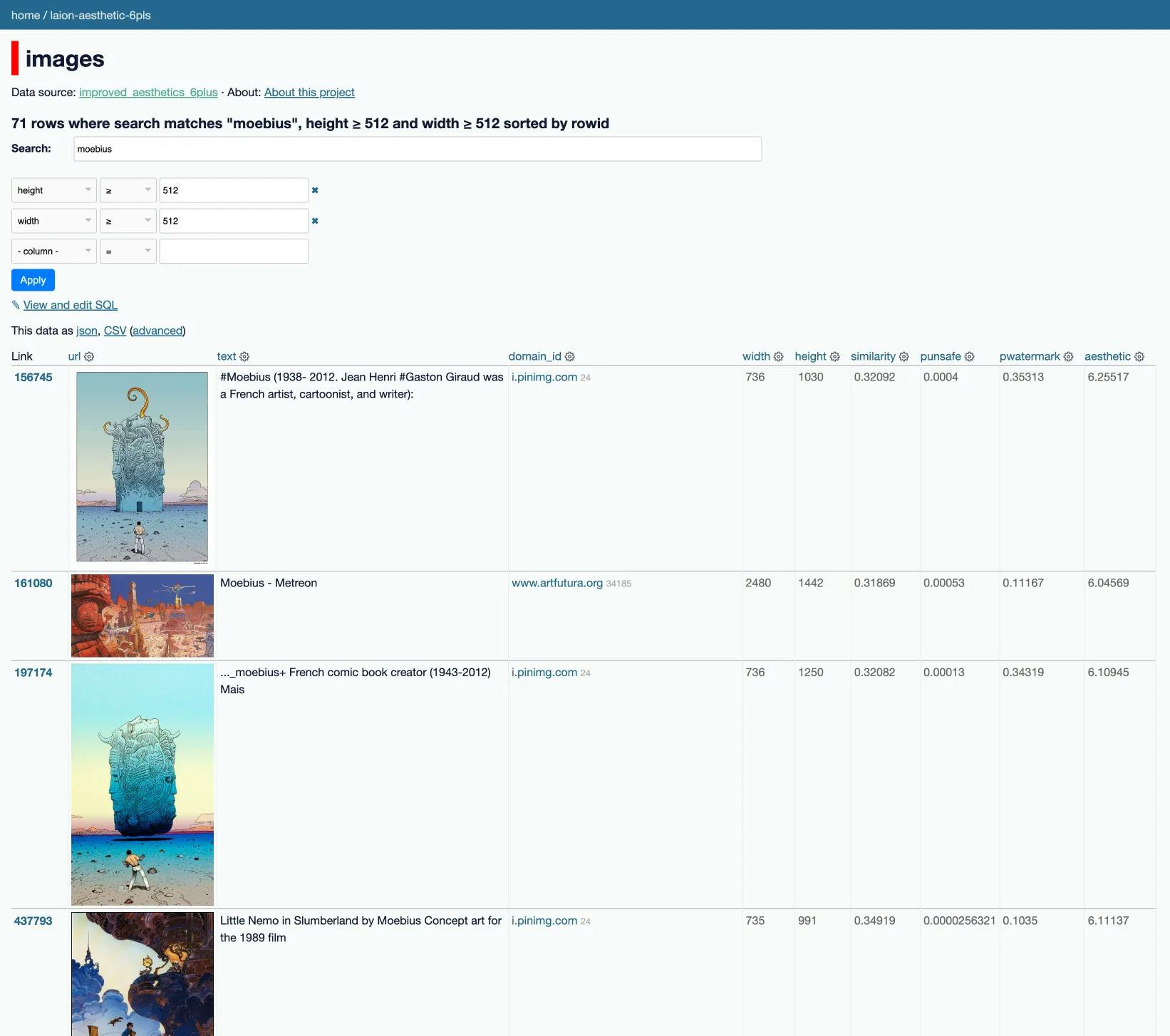
For the moebius style, I gathered 22 images.

For the killian eng style, I gathered 20 images

2. Train LoRA Weights
For detailed instructions on how to train LoRA weights, please refer to my last blog post.
tl;dr: create a .zip file of a collection of images, drag it into the instance_data field of this LoRA Training Model on Replicate. Then set the task dropdown to style, and click submit. This should take 6ish minutes to train and output a .safetensors file that can be used in your prompts.
When your weights are finished training, you should have URLs that look something like this. Make sure you save these URLs, as you will need them to generate images:
https://replicate.delivery/pbxt/abc123/moebius.safetensors
https://replicate.delivery/pbxt/abc123/killian-eng.safetensors
3. Will It Blend!?
This is where the fun begins!
My favorite LoRA-compatible generation model on Replicate is the Realistic Vision 1.3 model, so I’ll be using it throughout the rest of this post.
For all of these images, I used the following prompt and negative prompt pair, with some slight modifications:
PROMPT: ocean swells, blue, in the style of <1>, extremely detailed, fine lines, high resolution, 8k,
NEGATIVE PROMPT: building, character, ships, rocks, rock formation, islands, land
Experiment Results
Moebius Style
The Moebius style produced cartoony detailed ocean swells. Lots of tiny details and textures throughout the entire image, which looks great! The contrast seems a little low, but I also liked the lighting and color palette.
LoRA WEIGHTS: Moebius
LoRA SCALES: 0.1
-
PROMPT: ocean swells, blue, in the style of <1>, extremely detailed, fine lines, high resolution, 8k,
NEGATIVE PROMPT: building, character, ships, rocks, rock formation, islands, land

.webp&w=2048&q=75)
.webp&w=2048&q=75)
.webp&w=2048&q=75)
Killian Eng Style
The Killian Eng style produced similar, but more "organic" results. Lots of tangles and fine detailed line work. The color pallettes were a little more vibrant with reds and oranges, but the contrast was similarly muddled.
LoRA WEIGHTS: Killian Eng
LoRA SCALES: 0.1
-
PROMPT: ocean swells, blue, in the style of <1>, extremely detailed, fine lines, high resolution, 8k,
NEGATIVE PROMPT: building, character, ships, rocks, rock formation, islands, land

%25201.webp&w=2048&q=75)
%25201.webp&w=2048&q=75)
%25201.webp&w=2048&q=75)
Blending 2 LoRA Styles
So what happened when we tried to blend the two styles together? Interesting results, obviously!
It seems like blending the two styles produced a fairly consistent style, but the colors were more vibrant, the contrast was increased, and the detail work was more pronounced. There seems to be more lighting and shadow variance which is pretty cool, considering the solo styles were pretty flat and muddled.
LoRA WEIGHTS: Moebius|Killian Eng
LoRA SCALES: 0.1|0.1
-
PROMPT: ocean swells, blue, in the style of <1>, extremely detailed, fine lines, high resolution, 8k,
NEGATIVE PROMPT: building, character, ships, rocks, rock formation, islands, land


%25202.webp&w=2048&q=75)

Comparing Apples to Apples
In the next set of images, I'm using the same seed 232321 for all of the images. This gives us an apples-to-apples comparison of the solo styles compared to the blended style.
These are my favorite results, as it's cool to see the identical composition with varried lighting, color, and fine details.
LoRA WEIGHTS: Killian Eng
LoRA SCALES: 0.1
-
SEED: 232321
PROMPT: ocean swells, blue, combined style of <1>, extremely detailed, fine lines, high resolution, 8k,
NEGATIVE PROMPT: building, character, ships, rocks, rock formation, islands, land

LoRA WEIGHTS: Moebius
LoRA SCALES: 0.1
-
SEED: 232321
PROMPT: ocean swells, blue, combined style of <1>, extremely detailed, fine lines, high resolution, 8k,
NEGATIVE PROMPT: building, character, ships, rocks, rock formation, islands, land

LoRA WEIGHTS: Moebius, Killian Eng
LoRA SCALES: 0.1|0.1
-
SEED: 232321
PROMPT: ocean swells, blue, combined style of <1> and <2>, extremely detailed, fine lines, high resolution, 8k,
NEGATIVE PROMPT: building, character, ships, rocks, rock formation, islands, land

Interestingly, flipping the order that weights are defined (ie 1. Killian Eng, 2. Moebius vs. 1. Moebius, 2. Killian Eng) does make a slight difference, I can’t decide which I like better! It seems to impact both the lighting and the organic texture; but in very subtle ways.
LoRA WEIGHTS: Killian Eng. Moebius
LoRA SCALES: 0.1|0.1
-
SEED: 232321
PROMPT: ocean swells, blue, combined style of <1> and <2>, extremely detailed, fine lines, high resolution, 8k,
NEGATIVE PROMPT: building, character, ships, rocks, rock formation, islands, land

Using Prompts to Influence the Color Palette
Another interesting thing is that you can use the prompt and negative prompt as a way to influence the overall color composition of the image.
LoRA WEIGHTS: Moebius, Killian Eng
LoRA SCALES: 0.1|0.1
PROMPT: ocean swells, blue, combined style of <2> and <1>, extremely detailed, fine lines, high resolution, 8k,
NEGATIVE PROMPT: building, character, ships, rocks, rock formation, islands, land, orange, pink

LoRA WEIGHTS: Moebius, Killian Eng
LoRA SCALES: 0.1|0.1
PROMPT: ocean swells, blue, combined style of <2> and <1>, extremely detailed, fine lines, high resolution, 8k,
NEGATIVE PROMPT: building, character, ships, rocks, rock formation, islands, land, pink

Conclusion
This post really only begins to scratch the surface of what’s possible with LoRA styles, and I'm excited to continue exploring.
This ocean swells scene is sort of a weird place to start with explorations into blending styles because the styles are complex, detailed, and organic looking. It's somewhat difficult to see and understand the minute differences between the styles, but I saw enough variance and interestingness to continue exploring.
So I wouldn't call any of these results mind blowing, but I had fun. Some additional takeaways:
- It seems that when you’re applying a style to an existing prompt, it’s helpful to keep the
LoRA Scalevalues very small. I’ve been using0.1, and seeing reasonable results. - The scale values are “touchy”, if I turn them up too far, I get unexpected results.
- So far in my experiments, it still feels a little too iterative, I’m seeking creative control, and even if I define a specific style, I feel like I still spend a lot of time generating lots of revisions just to get in the right ballpark. Perhaps ControlNet or T2I Adapter will help — TBD! 🤷♂️
As always, if you have questions, comments, or concerns, please let me know!